
本文は、検索拡張生成(Retrieval Augmented Generation, RAG)技術とアルゴリズムに関する包括的な研究であり、各種手法を系統的に整理したものである。データ分割、ベクトル化、クエリ書き換え、クエリルーティングなど、RAGプロセス全体にわたる様々な手法に触れており、RAGに取り組んでいる皆さんならば、これらの技術の重要性がお分かりいただけるだろう。よく読んで理解し、お気に入り登録して何度も読み返し、実践することをお勧めする。
紹介
検索拡張生成(Retrieval Augmented Generation, RAG)は、データソースから情報を検索することで大規模言語モデル(Large Language Model, LLM)が回答を生成するのを支援する技術である。簡単に言えば、RAGは検索技術と大規模言語モデルのプロンプト機能を組み合わせたものであり、モデルに質問を投げかけ、検索アルゴリズムが見つけた情報を背景のコンテキストとして提供する。これらのクエリと検索されたコンテキスト情報は、LLMに送信されるプロンプトに統合される。
2025年までに、大規模言語モデルベースのシステムにおいて、RAGは最も人気のあるアーキテクチャの一つとなった。多くの製品がほぼ完全にRAGに基づいて構築されており、ウェブ検索エンジンとLLMを組み合わせたQ&Aサービスから、数え切れないほどの「データと対話する」アプリケーションまで多岐にわたる。
ベクトル検索の分野でさえ、このトレンドの影響を受けており、Faissベースの検索エンジンは2019年以前から存在していたにもかかわらず、である。Chroma、Weaviate.io、Pineconeといったベクトルデータベーススタートアップは、既存のオープンソースの検索インデックス(主にFaissとnmslib)を基盤として構築され、最近では入力テキストの追加ストレージやその他のツールも組み込まれている。
LLMベースのパイプラインおよびアプリケーション領域において、最もよく知られている2つのオープンソースライブラリは、それぞれ2022年10月と11月に設立されたLangChainとLlamaIndexである。これら2つのライブラリはChatGPTの発表に触発されて作成され、2023年に広く採用されるようになった。
本稿の目的は、主要な高度な検索拡張生成(Retrieval Augmented Generation, RAG)技術を系統的に整理し紹介することにあり、他の開発者がこの技術をより深く習得するのに役立つよう、LlamaIndexでの実装事例を重点的に参照している。
現存する問題は、大多数のチュートリアルが通常、利用可能なツールの豊富な多様性すべてを網羅せず、1、2の技術の具体的な実装方法のみを選択的に紹介していることである。
また、特筆すべきは、LlamaIndexとLangChainの両方が非常に優れたオープンソースプロジェクトであるということだ。それらは急速に発展し、今日までに蓄積された文書資料は、2016年の機械学習の教科書よりもはるかに膨大になっている。
基本RAG
本稿で議論する検索拡張生成(Retrieval Augmented Generation, RAG)パイプラインの出発点は、一連のテキスト文書である。これ以前のすべての内容、例えばデータの取得とロードは、YoutubeからNotionまで様々なデータソースに接続可能な強力なオープンソースのデータローディングツールによって実行される。
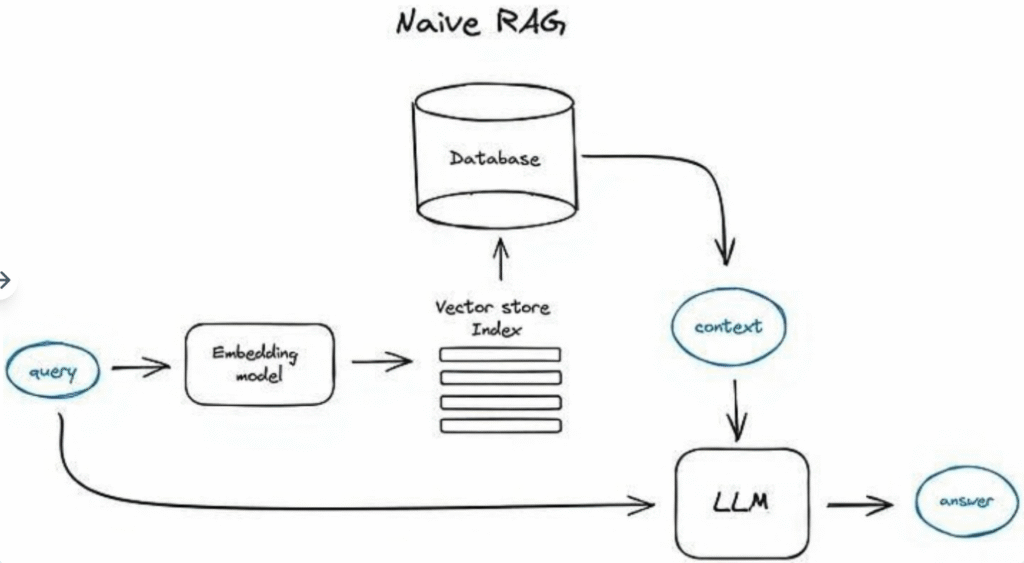
基本RAGの操作フローはおおむね以下の通りである。まず、テキストを小さなセグメントに分割し、何らかのTransformerエンコーダモデルを用いてこれらのテキストセグメントをベクトル形式に変換する。次に、すべてのベクトルをインデックスに集約する。最後に、検索ステップで見つけたコンテキスト情報に基づいてユーザーのクエリに答えるように、LLMに対するプロンプトを作成する。
実際の実行プロセスでは、同じエンコーダモデルを使用してユーザーのクエリをベクトルに変換し、このベクトルに基づいてインデックス内で検索を行う。システムは最も関連性の高い上位k個の結果を見つけ、データベースから対応するテキストセグメントを抽出し、これらのテキストセグメントをLLMのプロンプトへの入力コンテキスト情報として提供する。
プロンプトの具体的形式は以下のようになる:
python
def question_answering(context, query):
prompt = f"""三重バッククォート ```{query}``` で区切られたユーザークエリへの回答を、
三重バッククォート ```{context}``` で区切られたコンテキスト内の情報を使用して 生成してください。\
提供されたコンテキストに関連する情報がない場合は、自身の知識に基づいて回答を 試みてください、
ただし、回答の根拠となる関連するコンテキストがなかったことをユーザーに伝えてください。
簡潔に回答し、回答のサイズは80トークン未満に収めてください。
"""
response = get_completion(instruction, prompt, model="gpt-3.5-turbo")
answer = response.choices[0].message["content"]
return answerRAGパイプラインを改良する方法の中では、プロンプトエンジニアリングによる最適化が最もコスト効率の良い試みである。OpenAIが提供する包括的なプロンプト最適化ガイドを参照することを忘れないでください。
OpenAIはLLMプロバイダーとして市場をリードしているが、他にも多くの選択肢がある。例えば、AnthropicのClaude、MistralのMixtralのような最近人気の小型ながら強力なモデル、MicrosoftのPhi-2、そしてLlama2、OpenLLaMA、Falconなどの数多くのオープンソースの選択肢が、あなたのRAGパイプラインに多种多様な「頭脳」を提供する。
高度なRAG
さて、高度なRAG技術の概要を詳しく見ていこう。以下は、核心となるステップと関連アルゴリズムを示す模式図である。図の明確さと理解しやすさを保つため、いくつかの論理ループや複雑なマルチステップのエージェント動作は省略されている。
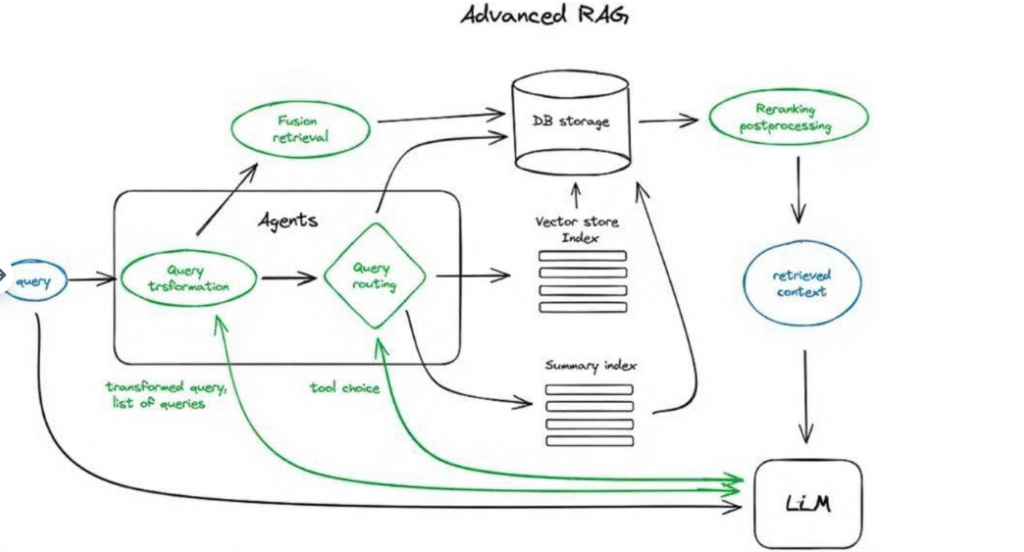
この模式図において、緑色の部分はこれから掘り下げていく核心的なRAG技術を表し、青色の部分はテキストを表す。すべての高度なRAGの概念がこの単一の模式図に明確に表示できるわけではないことに注意が必要である。例えば、コンテキストを拡張するために使用されるいくつかの方法は含まれていない——これらのトピックについては後続の議論でひとつずつ探究していく。
1. チャンキングとベクトル化
まず、文書の内容を表現するベクトルインデックスを作成する必要がある。そして、プログラム実行時に、これらのベクトルとクエリベクトル間の最小コサイン距離を検索することで、意味的に最も近いマッチを見つける。
1.1 チャンキング
Transformerモデルの入力シーケンス長は固定されている。入力コンテキストウィンドウが大きくても、1文または数文のベクトルでその意味を代表させる方が、数ページにわたるテキストを平均的にベクトル化するよりも通常効果的である。そのため、データをチャンキング処理し、文書をその元の意味を変えずに適切なサイズの段落に分割する必要がある(例えば、テキストを文や段落に分割し、単一の文を二つに切断しない)。このタスクには多种多様なテキスト分割ツールが利用できる。
考慮すべきパラメータの一つはチャンクサイズであり、これは使用する埋め込みモデルとそのトークン処理能力に依存する。例えば、BERTベースの標準的なTransformerエンコーダモデルは最大512トークンを処理できるが、OpenAIのada-002は8191トークンのようなより長いシーケンスを処理できる。しかし、ここでトレードオフとなるのは、LLMに推論を行うための十分なコンテキストを提供することと、効率的な検索を実現するために十分に具体的なテキスト埋め込みを実現することである。チャンクサイズの選択に関する研究は、LlamaIndexのNodeParserクラスで見つけることができ、このクラスは独自のテキストスプリッターの定義、メタデータ、ノード/チャンク関係など、いくつかの高度なオプションを提供している。
1.2 ベクトル化
次のステップは、これらのテキストチャンクを埋め込むためのモデルを選択することである。選択可能なモデルは多种多様あり、検索最適化モデルであるbge-largeやE5埋め込みシリーズのようなモデルを使用することをお勧めする。最新のモデル情報についてはMTEBランキングを参照できる。
チャンキングとベクトル化のエンドツーエンドの操作を実現するには、LlamaIndexでの完全なデータ入力フローの例を参照されたい。
2. 検索インデックス
2.1 ベクトルストアインデックス
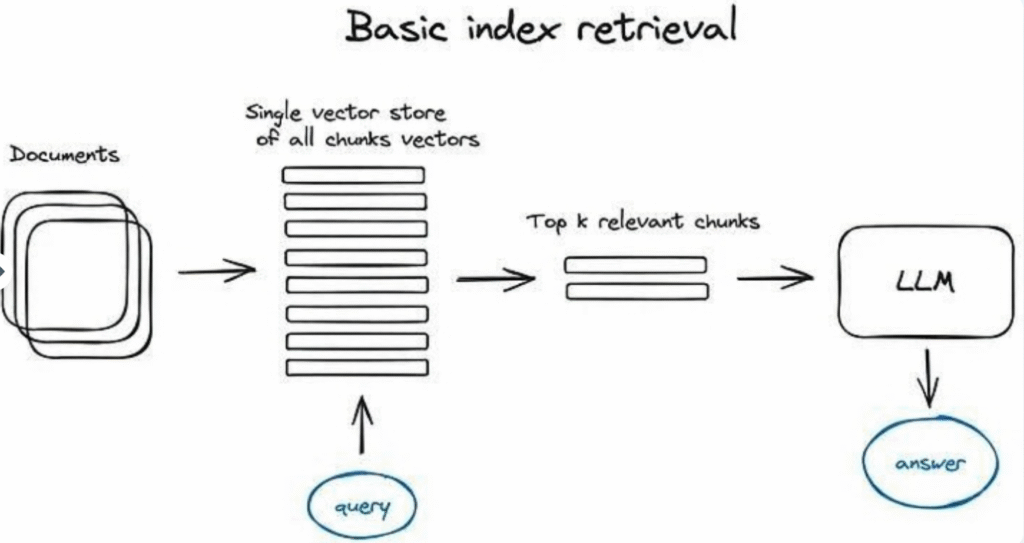
この模式図及び本文中の以降の内容では、模式図の簡潔さを保つため、エンコーダ(Encoder)の過程を省略し、直接クエリの内容をインデックスに送信している。もちろん、クエリの内容はその前にベクトル形式に変換されている。これは前k個のチャンクの処理にも同様に適用される——インデックスが実際に検索するのはチャンクそのものではなく前k個のベクトルであるが、ここでは、インデックスからこれらのチャンクを抽出するのは単純なステップであるため、チャンクの形式でそれらを提示している。
RAGパイプラインにおいて、極めて重要な部分は、前のステップで生成したベクトル化された内容を保存するための検索インデックスである。最も基本的な実装方法は、フラットインデックスを使用するもので、これは力任せ法でクエリベクトルとすべてのチャンクベクトル間の距離を計算する。
10,000要素を超える大規模検索に対して最適化された効率的な検索インデックスは、例えばFaiss、nmslib、あるいはAnnoyのようなベクトルインデックスを使用する。これらのインデックスは、クラスタリング、木構造、またはHNSWアルゴリズムなどの近似最近傍探索法を採用している。
OpenSearchやElasticSearchのようなマネージドソリューションやベクトルデータベースもあり、これらは内部で第1ステップで記述されたデータ投入プロセスを処理する(例:Pinecone、Weaviate、Chroma)。
選択するインデックスの種類、データ、検索要件に応じて、ベクトルと一緒にメタデータを保存し、その後メタデータフィルターを使用して特定の日付やソースの情報を検索することもできる。
LlamaIndexは多种多様なベクトルストアインデックスタイプをサポートするだけでなく、リストインデックス、ツリーインデックス、キーワードテーブルインデックスといった、より単純なインデックス実装もサポートしている——これらのインデックスタイプについては後述の融合検索でさらに議論する。
2.2 階層インデックス
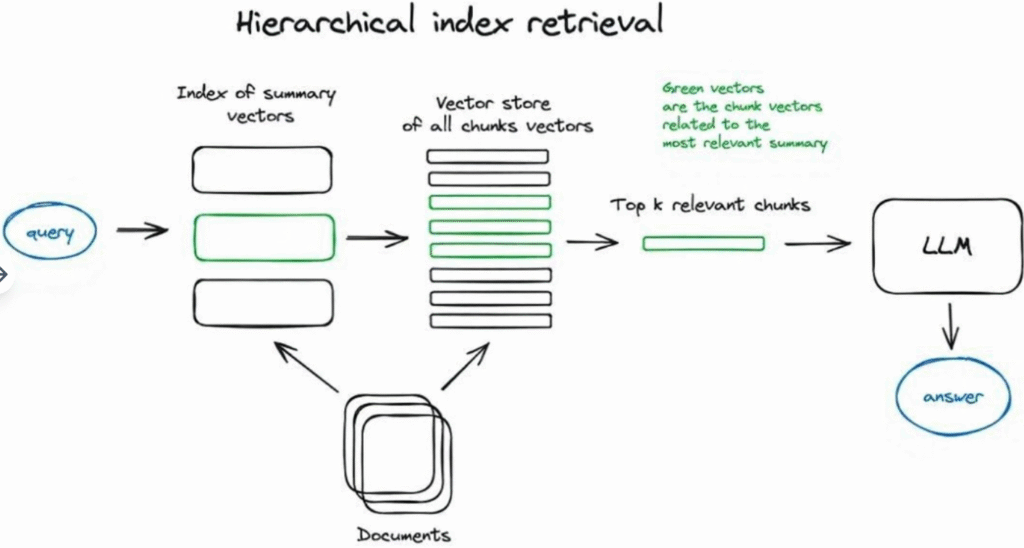
大量の文書から情報を検索する必要がある場合、関連情報を見つけ、ソース引用を含む統一された回答に要約するためには、効率的な検索方法が極めて重要である。大規模データベースを扱う場合、要約で構成されるインデックスと文書チャンクで構成されるインデックスの2つを作成し、2段階で検索を行うという効果的な方法がある。まず要約を通じて関連文書をフィルタリングし、次にこの関連グループ内でのみ検索を行う。
2.3 仮説的質問とHyDE
もう一つの方法は、LLMに各チャンクに対して仮説的な質問を生成させ、これらの質問をベクトル形式で埋め込むことである。実行時には、この質問ベクトルのインデックスに対してクエリ検索を行い(インデックス内のチャンクベクトルを問題ベクトルで置き換える)、検索後に元のテキストチャンクをLLMに回答を得るためのコンテキストとして送信する。この方法は、クエリと仮説的質問の間の意味的類似性が高いため、検索品質を向上させる。
HyDEと呼ばれる逆の論理を用いる方法もある——ユーザーはLLMにクエリに基づいて仮説的な回答を生成させ、その回答のベクトルをクエリベクトルと一緒に使用して検索品質を向上させる。
2.4 コンテキスト拡張
ここでの考え方は、検索品質を向上させるために小さなチャンクを検索すると同時に、LLMが推論分析を行うための周囲のコンテキストを追加するというものである。
コンテキストを拡張するには2つの方法がある——検索された小さなチャンクの周囲に文を追加してコンテキストを拡張する方法と、文書を複数の小さなサブチャンクを含む大きな親チャンクに再帰的に分割する方法である。
2.4.1 センテンスウィンドウ検索
この方式では、文書内の各文が個別に埋め込まれ、ベクトル化される。これにより、クエリからコンテキストへのコサイン距離検索の精度が向上する。
見つけたコンテキストをより良く推論するために、検索されたキーセンテンスの前後にk個の文を拡張し、この拡張されたコンテキストをLLMに送信する。

緑色の部分は、インデックス検索で見つかった文のベクトル表現を表し、黒色と緑色の部分全体が大規模言語モデル(LLM)に入力され、提供されたクエリを分析する際にそのコンテキスト範囲を拡大することを目的とする。
2.4.2 自動マージ検索器(別名:親文書検索器)
ここでの考え方はセンテンスウィンドウ検索器と非常に似ている——より細かい情報の断片を検索することを目的とし、その後、LLMに推論のためのコンテキスト情報を提供する前に、コンテキストウィンドウを拡大する。文書は小さなサブチャンクに分割され、これらのサブチャンクはより大きな親チャンクに対応する。
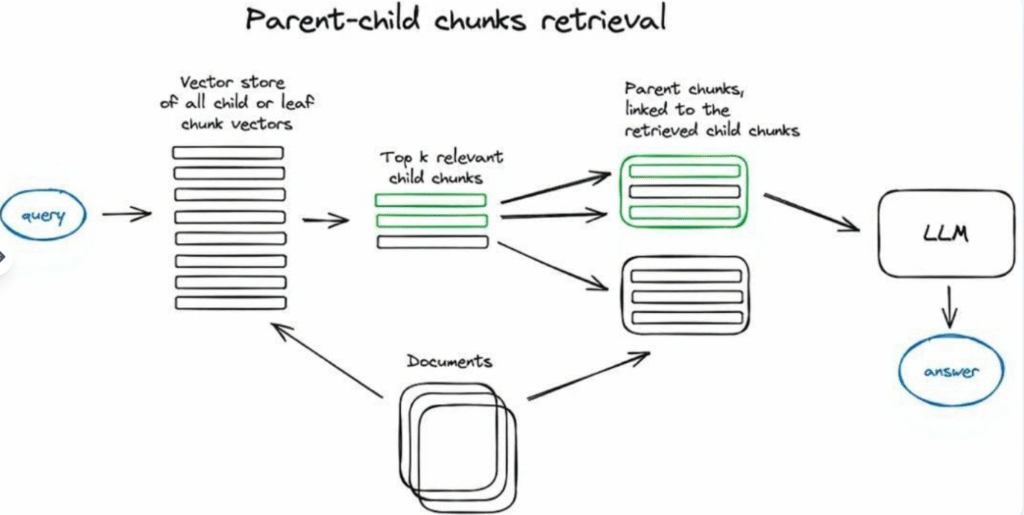
文書は階層的なチャンク構造に分割され、その後、最小のリーフチャンクがインデックスに送信される。検索プロセスでは、k個のリーフチャンクが検索される。n個のチャンクが同じ大きな親チャンクを指している場合、これらのサブチャンクを親チャンクで置き換え、それを大規模言語モデル(LLM)に答えを生成するために提供する。
検索プロセスでは、まず小さなデータチャンクを取得する。検索された上位k個のチャンクの中に、同じ親ノード(すなわち、より大きなチャンク)を指すn個以上のチャンクが存在する場合、我々はこの親ノードで元々LLMに提供されていたコンテキスト内容を置き換える。このプロセスは、いくつかの小さなチャンクを自動的に1つの大きな親チャンクにマージするのに似ているため、この名前が付けられている。この検索は子ノードのインデックス内でのみ行われることに注意が必要である。この方法をより深く理解したい場合は、LlamaIndexの再帰検索器とノード参照に関するチュートリアルを参照のこと。
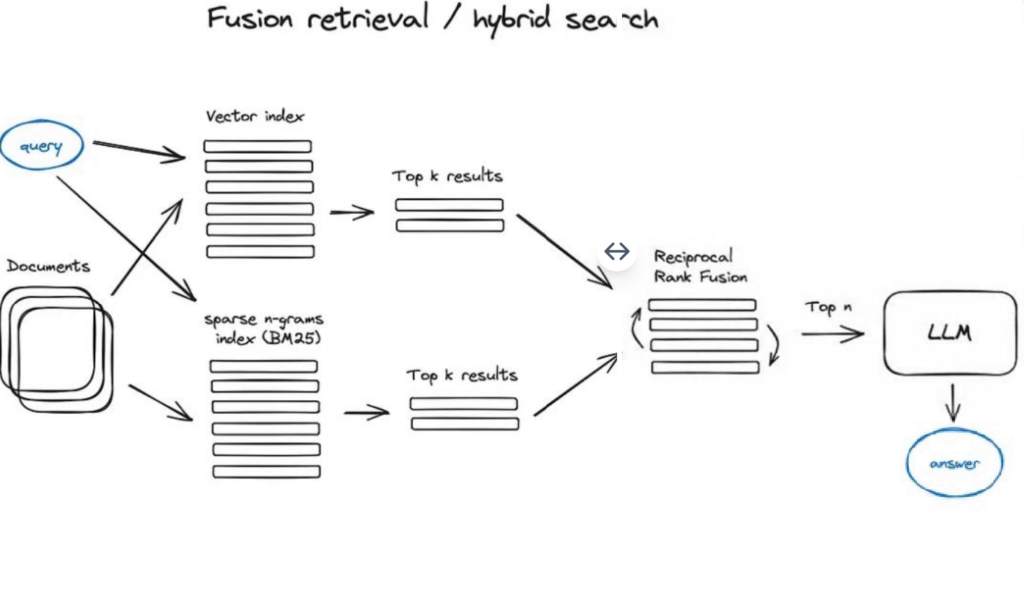
2.5 融合検索またはハイブリッド検索
これは比較的旧来の概念であり、2つの異なる検索方法を組み合わせる。一つは、スパース検索アルゴリズム(TF-IDFや業界標準のBM25など)を使用したキーワードベースの従来の検索方法、もう一つは現代的な意味検索またはベクトル検索である。これら2つの方法は融合され、統合された検索結果を生成する。
ここでの鍵は、異なる類似度スコアを持つ検索結果を正しく結合することである。この問題は通常、相互ランク融合アルゴリズムによって解決され、このアルゴリズムは最終的な出力を生成するために検索結果を再ランク付けする。
クエリ変換の原則を説明
LangChainでは、この機能はEnsemble Retrieverクラスを通じて実装されており、これはユーザーが定義した一連の検索器(例えば、FaissベクトルインデックスとBM25ベースの検索器)を結合し、相互ランク融合アルゴリズム(RRF)を使用して結果を再ランク付けする。
LlamaIndexでも、この機能は非常に似た方法で実装されている。
ハイブリッドまたは融合検索は通常、より良い検索結果を提供する。なぜなら、クエリと保存文書間の意味的類似性とキーワードマッチングの両方を考慮した、互いに補完する2つの検索アルゴリズムを組み合わせているからである。
3. 再ランク付けとフィルタリング
したがって、上述のいずれかのアルゴリズムを使用して検索結果を得た後、フィルタリング、再ランク付け、または何らかの変換を通じてこれらの結果をさらに最適化する必要がある。LlamaIndexは、類似度スコア、キーワード、メタデータなどに基づいて結果をフィルタリングする、またはLLM、Sentence-Transformerクロスエンコーダ、Cohereの再ランキングエンドポイント、日付などのメタデータに基づく新しさなど——考えられるほとんどすべての状況をカバーする——他のモデルを使用して再ランク付けする多种多様な後処理器を提供する。
これは、検索されたコンテキストが大規模言語モデル(LLM)に入力され、最終的な答えが得られる前の最後のステップである。
さて、クエリ変換やルーティングのようなより高度なRAG技術を紹介する。これら両方ともLLMを利用するため、エージェントの行動——我々のRAGパイプラインに関わる複雑な大規模言語モデル推論ロジックの一部を代表する。
4. クエリ変換
クエリ変換は、推論エンジンとしてLLMを使用してユーザー入力を修正し、それによって検索品質を向上させる一連の技術である。この目標を達成するには多种多様な異なる方法がある。
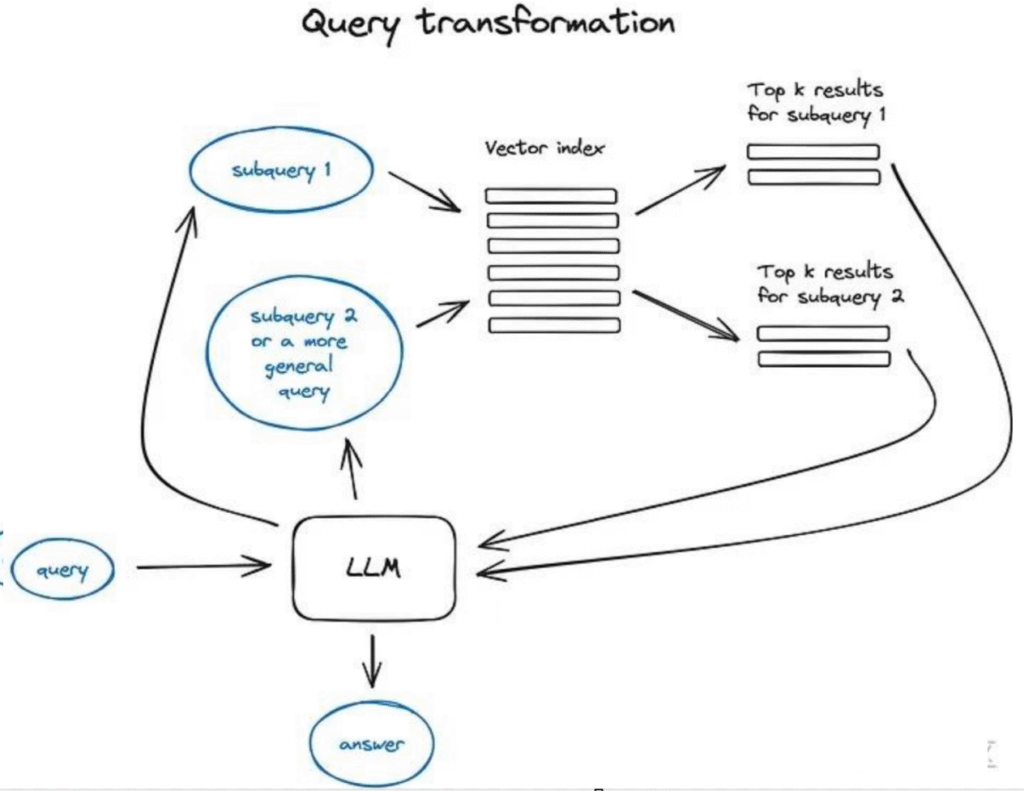
クエリが複雑な場合、大規模言語モデル(LLM)はそれをいくつかのサブクエリに分解することができる。例えば、以下のように質問する場合:
——「Githubで、LangchainとLlamaIndex、どちらのフレームワークのスターが多いですか?」—— このような比較がコーパス内に直接見つかる可能性は低いため、この問題を2つのより単純で具体的な情報検索のサブクエリに分解することは理にかなっている:
——「LangchainのGithubスター数は?」
——「LlamaIndexのGithubスター数は?」
これらのクエリは並行して実行され、その後、検索されたコンテキストは初期クエリに対する最終的な答えをLLMが統合するための一つのプロンプトに組み合わされる。両ライブラリでこの機能が実装されている——LangChainではマルチクエリ検索器として、LlamaIndexではサブ問題クエリエンジンとして。
フォールバックプロンプト
大規模言語モデルを使用してより一般的なクエリを生成し、取得したより一般的または高度なコンテキストを検索することは、私たちのオリジナルクエリに対する答えの基礎を築くのに役立つ。また、オリジナルクエリに対しても検索を行い、最終的に2つのコンテキスト入力をLLMに渡して答えを生成する。これはLangChainでの実装方法である。
クエリ書き換え 大規模言語モデルを使用して初期クエリを再構築し、検索効果を向上させる。LangChainとLlamaIndexの両方に実装があるが、多少異なり、ここではLlamaIndexのソリューションの方がより強力だと考えている。
参照引用
この部分には番号が付けられていない。なぜなら、これは検索改良技術というよりはツールに近く、非常に重要であるにもかかわらず、そのように位置づけられているからである。
答えを生成するために複数のソースを使用した場合——初期クエリが複雑であったため(複数のサブクエリを実行し、検索されたコンテキストを一つの答えに統合する必要があった)、または異なる文書で単一クエリの関連コンテキストを見つけたため——という状況で、私たちが正確にソースを逆参照できるかどうかという問題が生じる。
これを行うにはいくつかの方法がある:
- この参照タスクを私たちのプロンプトに挿入し、LLMに使用したソースのIDに言及するよう要求する。
- 生成された応答の部分を私たちのインデックス内の元のテキストチャンクと照合する——LlamaIndexはこの状況のために、ファジーマッチングに基づく効率的なソリューションを提供している。ファジーマッチングを知らない場合、これは非常に強力な文字列マッチング技術である。
5. 対話エンジン
単一の検索クエリに対して繰り返し効果的に動作する効率的なRAGシステムを構築する上で、次の重要な進展は、対話コンテキストを考慮するチャットロジックの開発である。その原理はLLM時代以前の古典的なチャットボットに似ている。
このロジックの開発は、ユーザーがフォローアップの質問をしたり、前後の対話における指示語や以前の対話コンテキストに関連する任意のコマンドを処理したりすることをサポートするために行われた。この問題を解決するために、研究者たちはユーザーのクエリを処理する際にチャットのコンテキストも考慮するクエリ圧縮技術を採用した。
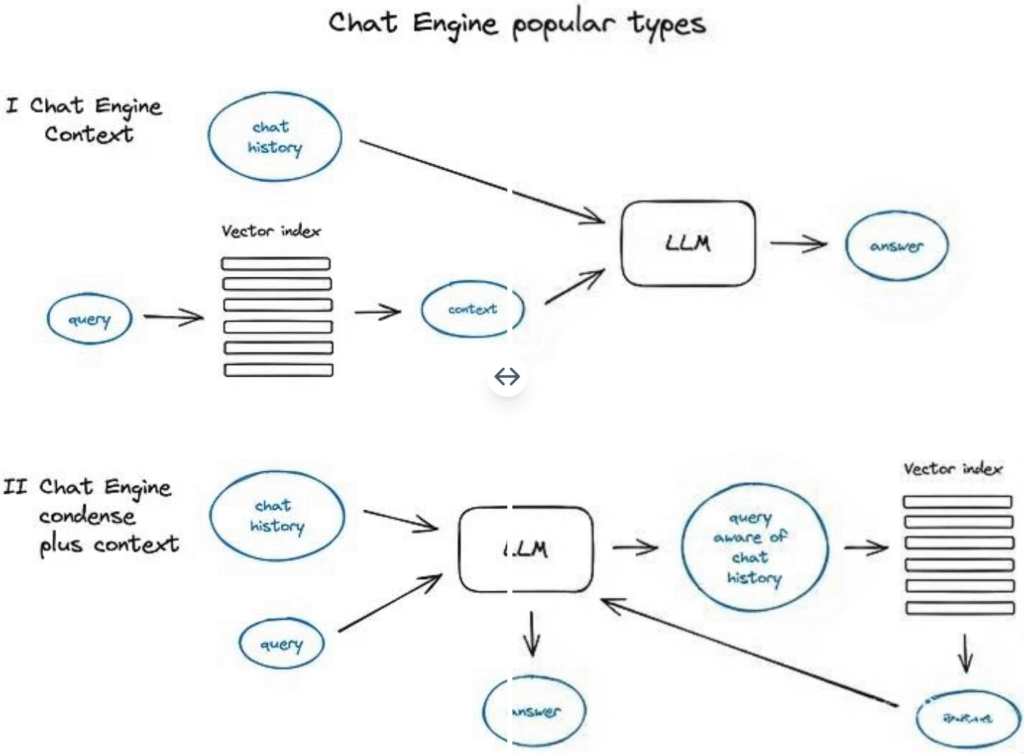
コンテキストの圧縮については、いくつかの異なる方法がある——
人気が高く比較的単純な方法は、ContextChatEngineを使用することである。このエンジンはまずユーザークエリに関連するコンテキストを検索し、その後、それをメモリバッファからのチャット履歴と一緒にLLMに送信し、LLMが前のコンテキストを理解した上で次の回答を生成することを保証する。
より複雑な例は、CondensePlusContextModeである。このモードでは、それぞれのやり取りにおけるチャット履歴と最後のメッセージが新しいクエリに圧縮される。その後、このクエリはインデックスシステムに送信され、検索されたコンテキストは元のユーザーメッセージと一緒に戻される。
特筆すべきは、LlamaIndexがOpenAIエージェントベースのチャットエンジンもサポートしており、より柔軟なチャットモードを提供し、LangchainもOpenAIの機能APIをサポートしていることである。
他にもReAct Agentのようなチャットエンジンタイプがあり、この部分の内容は第7節で詳しく紹介する。
6. クエリルーティング
クエリルーティングは、ユーザーのクエリに対して次に取るべき行動を決定する、LLMベースの意思決定ステップである。通常のオプションには、回答の要約、特定のデータインデックスに対する検索の実行、または複数の異なる経路を試してそれらの結果を一つの答えに統合することが含まれる。
クエジルーターはまた、ユーザークエリを処理するための適切なインデックスまたはより広範なデータストアを選択するためにも使用される。これには、従来のベクトルストア、グラフデータベースまたはリレーショナルデータベース、またはインデックス階層構造など、複数のデータソースが関わる可能性がある。複数文書ストアの場合、一般的な設定は、要約インデックスと別の文書チャンクベクトルのインデックスである。
クエジルーターの設定は、それが行える選択を決定することを含む。ルーティングオプションの選択は、LLMの呼び出しを通じて実現され、返される結果は、クエリを指定されたインデックスに誘導するために事前に定義された形式に従う。あるいは、マルチエージェント行動が関わる場合、以下のマルチ文書エージェント模式図に示すように、サブチェーン或其他のエージェントに誘導することができる。
LlamaIndexとLangChainの両方がクエリルーターをサポートしている。
7. RAGにおけるエージェント
エージェント(LangChainとLlamaIndexの両方でサポートされている)は、最初のLLM APIがリリースされて以来存在している。その核心的な理念は、推論能力を持つLLMに、一連のツールと完了すべきタスクを提供することである。これらのツールには、決定論的関数(コード機能や外部APIなど)或其他のエージェントが含まれる可能性がある。このLLMを連鎖させるという考え方がLangChainの命名のきっかけとなった。
エージェント自体は非常に広範な分野であり、RAGの概要では深入りできないため、エージェントベースのマルチ文書検索ケースについて直接議論を続け、OpenAIアシスタントについて簡単に紹介する。OpenAIアシスタントは、最近のOpenAI開発者会議でGPTとして提案された比較的新しい概念であり、以下で説明するRAGシステムで役割を果たしている。
OpenAI Assistantsは、私たちが以前オープンソースプロジェクトで見た、LLMを囲む必須のツールの多くを統合している——チャット履歴管理、ナレッジベースストレージ、ドキュメントアップロードインターフェース、そして最も重要なのは、機能呼び出しAPIである。このAPIの重要な機能は、自然言語リクエストを外部ツールやデータベースクエリのAPI呼び出しに変換できることである。
LlamaIndexでは、OpenAIAgentクラスがこれらの高度な機能を融合し、ChatEngineおよびQueryEngineクラスと組み合わせることで、知識ベースの、コンテキスト認識能力を持つチャット体験を提供する。さらに、これは一つの対話インタラクションで複数のOpenAI機能を呼び出すことができ、真のインテリジェントエージェント行動を実現する。
次に、マルチドキュメントエージェントスキームを理解しよう——これは各ドキュメントでエージェント(OpenAIAgent)を初期化するというかなり複雑な設計に関わり、このエージェントはドキュメント要約処理だけでなく、古典的な質疑応答フローも実行できる。また、クエリタスクを各ドキュメントエージェントに割り当て、最終的な答えを統合するトップレベルエージェントもある。
各ドキュメントエージェントは2つのツール——ベクトルストアインデックスと要約インデックス——を装備しており、受信したクエリに基づいてどちらのツールを使用するかを決定する。トップレベルエージェントにとって、すべてのドキュメントエージェントはそのツールであり、スケジューリング可能である。
このスキームは、各エージェントが行う複雑なルーティング決定に関わる高度なRAGアーキテクチャを示している。このアーキテクチャの利点は、異なる文書で記述された異なるソリューションまたはエンティティ、およびそれらの要約を比較できること、そして同時に古典的な単一文書の要約処理と質疑応答フローもサポートすることである——これは実際、文書コレクションとのインタラクションにおける大多数の一般的なユースケースをカバーしている。
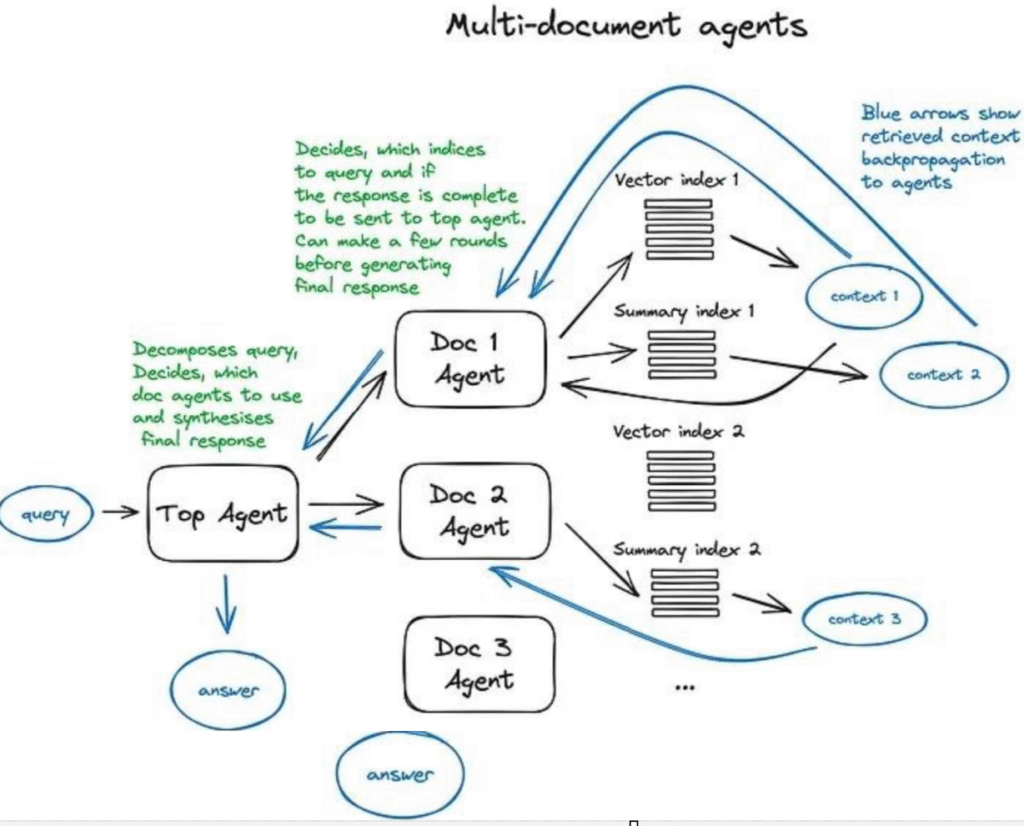
これは、クエリのルーティング処理とエージェントのインテリジェントな行動パターンを含む、マルチドキュメントエージェントの動作方法を示すスキームである。
この複雑なスキームの欠点は、画像から理解できる——エージェント内部で大規模言語モデル(LLM)との多数の反復が必要なため、処理速度が遅い。RAGアーキテクチャでは、LLMの呼び出しが常に最も時間のかかるステップであり、検索は設計上の考慮から速度が最適化されていることに注意する必要がある。したがって、多数の文書を含むストレージシステムの場合、このスキームを簡素化して拡張性を高めることをお勧めする。
8. 応答合成器
これはRAGアーキテクチャの最終ステップである——私たちが注意深く収集したすべてのコンテキストとユーザーの予備的なクエリに基づいて答えを生成する。
最も簡単な方法は、すべての関連性の高いコンテキストとクエリを直接連結し、一度にLLMに入力することである。
しかし、取得したコンテキストを洗練させ、それに基づいてより正確な答えを生成するためにLLMを複数回使用する、より複雑な方法もある。応答合成の主要な方法には以下が含まれる:
- 取得したコンテキストをチャンクに分け、大規模言語モデル(LLM)に逐次送信し、それによって反復的に答えを洗練させる。
- 取得したコンテキストを要約し、入力プロンプトに適合させる。
- 異なるコンテキストチャンクに基づいて複数の答えを生成し、その後、これらの答えを連結または要約する。
詳細は応答合成器モジュールのドキュメントを参照されたい。
エンコーダとLLMのファインチューニング
この方法は、私たちのRAGアーキテクチャにおける2つの深層学習モデルのうちの1つを精细に調整することを含む。これは、コンテキスト検索の効果に影響を与える高品質な埋め込みを生成する責任を持つTransformerエンコーダ、または提供されたコンテキストを最適に利用してユーザーの質問に答えるLLMのいずれかであり、幸いなことに後者は少数事例学習に非常に長けている。
現在、重要な利点は、GPT-4のようなハイエンドの大規模言語モデルを使用して高品質の合成データセットを作成できることである。
しかし同時に、専門家チームが大規模で注意深く選別および洗浄されたデータセットで訓練したオープンソースモデルを、迅速かつ簡単に調整すること(特に小型の合成データセットを使用する場合)は、モデルの全体的な性能と能力を制限する可能性があることを認識しなければならない。
エンコーダのファインチューニング
私は以前、検索最適化された最新のTransformerエンコーダがすでに非常に効率的であるため、エンコーダのファインチューニングに懐疑的であった。
そこで、私はLlamaIndex notebook環境でbge-large-en-v1.5(本稿執筆時点で、このモデルはMTEBランキングでトップ4)のファインチューニング効果をテストした。テスト結果は、検索品質が2%向上したことを示した。この向上は非常に顕著ではないが、特定の分野のデータセット向けにRAGを構築する際に、このファインチューニングオプションを知っておくことは有益である。
ランカーのファインチューニング
もう一つの伝統的な選択肢は、ベースエンコーダの効果に完全に満足していない場合、クロスエンコーダを使用して検索結果を再評価することである。
この方法の仕組みは次の通り——クエリ文と検索された上位k個のテキストチャンクを一緒にクロスエンコーダに渡し、各部分をSEPトークンで区切り、関連するテキストチャンクに対しては1を、関連しないものに対しては0を出力するようにファインチューニングする。この調整プロセスの良い例はここで見つけることができ、結果はクロスエンコーダのファインチューニングを通じて、ペアワイズスコアが4%向上したことを示している。
LLMのファインチューニング
OpenAIは最近、大規模言語モデルファインチューニングAPIを発表し、LlamaIndexもRAG環境下でGPT-3.5-turboをファインチューニングし、それによってGPT-4の知識の一部を「吸収」させる方法を紹介するチュートリアルを提供している。このプロセスは、ドキュメントを1つ使用し、GPT-3.5-turboを使用して問題を生成し、次にGPT-4にそのドキュメントの内容に基づいてこれらの問題に答えさせ(つまり、GPT-4駆動のRAGアーキテクチャを構築)、その後、GPT-3.5-turboをファインチューニングし、これらの問題と答えのペアを処理するように訓練することを含む。この方法により、ragasフレームワークを使用したRAGアーキテクチャ評価は、忠実性指標が5%向上したことを示し、これはファインチューニングされたGPT-3.5-turboが提供されたコンテキストを利用して回答を生成する際に、元のモデルよりも優れたパフォーマンスを示したことを意味する。
Meta AI Researchの最近の論文『RA-DIT: Retrieval Augmented Dual Instruction Tuning』は、より複雑な方法を示しており、クエリ、コンテキスト、答えの三組に基づいて、LLMと検索器(元論文ではデュアルエンコーダ)の両方を同時にファインチューニングする技術を提案している。具体的な実施細節は関連ガイドを参照されたい。この技術は、OpenAI大規模言語モデルをファインチューニングAPIを通じて微調整するために使用され、同時にオープンソースモデルLlama2(元論文で説明されているように)にも使用され、知識集約型タスクの指標で約5%の向上(RAGを使用するLlama2 65Bと比較して)を実現し、常識推論タスクでも一定の向上が見られた。
評価
RAGシステムの性能評価は通常、答えの全体的な関連性、答えの根拠、忠実性、および検索されたコンテキストの関連性など、複数の独立した指標を含む。
前述のRagasは、生成された答えの品質を評価する指標として主に忠実性と答えの関連性を利用し、従来のコンテキスト精度と再現率を使用してRAGアーキテクチャの検索効果を評価する。
Andrew Ngが最近発表した素晴らしい短編コース『高度なRAGの構築と評価』では、LlamaIndexと評価フレームワークTruelensを組み合わせ、RAGの3大評価次元を提案した:検索されたコンテキストとクエリの関連性、答えの根拠(大規模言語モデルの答えが提供されたコンテキストによってどの程度支持されているか)、およびクエリに対する答えの関連性。
最も重要でかつ制御しやすい指標は、検索されたコンテキストの関連性である。実際、高度なRAGアーキテクチャの第1~7部およびエンコーダとランカーのファインチューニング部は、この指標を向上させることを目的としており、第8部と大規模言語モデルのファインチューニングは、答えの関連性と根拠の向上に重点を置いている。
単純な検索器評価プロセスの良い例はここで見つけることができ、それはエンコーダのファインチューニング部で適用されている。ヒット率だけでなく、平均相互ランク(検索エンジンで一般的に使用される指標)、および生成された答えの忠実性と関連性指標を考慮したより高度な方法は、OpenAI cookbookで示されている。
LangChainは、高度な評価フレームワークLangSmithを提供しており、カスタム評価方法を実現できるだけでなく、RAGアーキテクチャ内部で実行されるプロセスを監視し、それによってシステムの透明性を高めることができる。
もしLlamaIndexを使用して構築しているのであれば、rag_evaluator_llamaパッケージがあり、これはパブリックデータセットを利用してあなたのアーキテクチャを評価するための便利なツールを提供する。
結論
私はRAGの核心となるアルゴリズムアプローチを概説し、いくつかの例を通じてそれらを示すよう努めた。これが、あなた自身のRAGアーキテクチャでいくつかの新しいアイデアを試すきっかけとなること、または今年発表された多くの技術をより系統的に理解するのに役立つことを願っている——私にとって、2023年はこれまでで最もエキサイティングな機械学習の年であった。
他にも探求すべき多くの側面がある。例えば、ウェブ検索ベースのRAG(LlamaIndex、webLangChainのRAGsなど)、エージェントアーキテクチャのより深い研究、および大規模言語モデルの長期記憶機能に関するいくつかの構想などである。
本番環境におけるRAGシステムの主な課題は、答えの関連性と忠実性以外に、速度も含まれる。特に、より柔軟なエージェントベースのスキームを採用する場合にはそうである。しかし、これは別の議論が必要である。ChatGPTや他の多くのアシスタントが採用しているストリーミング特性は、ランダムなサイバーパンクスタイルではなく、ユーザーが知覚する答えの生成時間を短縮するためのものである。これが、私が小型の大規模言語モデル、および最近リリースされたMixtralやPhi-2などの製品が将来大いに活躍すると考える理由である。
コメントなし